


Regex is ubiquitous in the programming world because of its usefulness as a rule-based text parsing language. Programmers find comfort in the idea of writing explicit, modifiable rules in order to parse text. This is in contrast with black-box statistical models, which cannot be modified when things go wrong – and things go wrong with today’s NLP packages almost immediately when used to perform a real-world NLP task.
Programmers are left with the impossibly unreadable and restricted rule system of Regex, knowing that the black box, statistical systems of turn-key NLP packages are useless. If they had their way, they would extend Regex’s rules to encompass all of NLP.
Lucky for them, the newly open-source language NLP++ does exactly that.
Over 30 Years in the Making
Amnon Meyers and I began working in NLP in the 1980s, finally joining forces in 1990. He brought his Conceptual Grammar knowledge representation and I came with bottom-up, island-driven rule parsing that I had developed during my days in the industry. Amnon and I worked in McDonnell Douglas’ AI group and participated in DARPA’s Message Understanding Conferences (MUC), building systems that would eventually lead to the NLP++ framework. We both continued NLP work at the AI group in Space Park at TRW.
In 1997, I joined I-Search, a resume processing company. Unbeknownst to me, the CEO of I-Search was inspired to create the company after seeing one of my NLP demos at TRW. They had a resume processing system based on Regex and wanted to improve it. The person who wrote the Regex code moved on.
When I first examined the Regex code for processing the resumes, unsurprisingly I found it impossible to decipher and improve. I told the CEO that I would like to rewrite the entire processor using C++ and “my” way of doing things. The new system worked quite well, processing 8000 resumes a day from OCR and text documents and unlike Regex, it was easy to correct when problems arose.
NLP++ Framework is Born
In 1998, Amnon secured funding for a startup to create a new NLP technology and lured me away from I-Search. There we developed our “dream” programming language for NLP, combining my bottom-up rule system, Amnon’s conceptual grammar as the knowledge base, and adding a syntactic tree structure, a rule system, a visual editor to help with developing and debugging, and creating the most crucial part: the NLP++ language. This NLP framework enabled programmers to focus on the NLP tasks without worrying about the bookkeeping aspects. The result was quite spectacular.
Amnon and I knew that NLP++ would eventually become a Regex killer. But at that time, our company focused on creating and licensing NLP analyzers for private companies.
During the 2000s and 2010s, NLP++ was used for numerous projects, including a sentiment analyzer for NASDAQ. But with the popularity of statistical methods such as machine learning and neural networks, hand-built NLP analyzers fell out of favor.
NLP++ languished through the 2000s and into the 2010s. In November of 2014 I was hired by LexisNexis in Florida as an ECL programmer. There I demonstrated NLP++ and was immediately promoted to the super computing group there. Over the next 8 years, I took the NLP++ framework from its early 2000s framework to a modern system.
As part of this modernization, Amnon dissolved the company that created NLP++ and in December 2018, NLP++ became open source. The NLP++ language interpreter evolved into the “NLP Engine” that ran on all major platforms, and the Windows-only Editor “VisualText” transformed into the NLP++ language extension for VSCode.
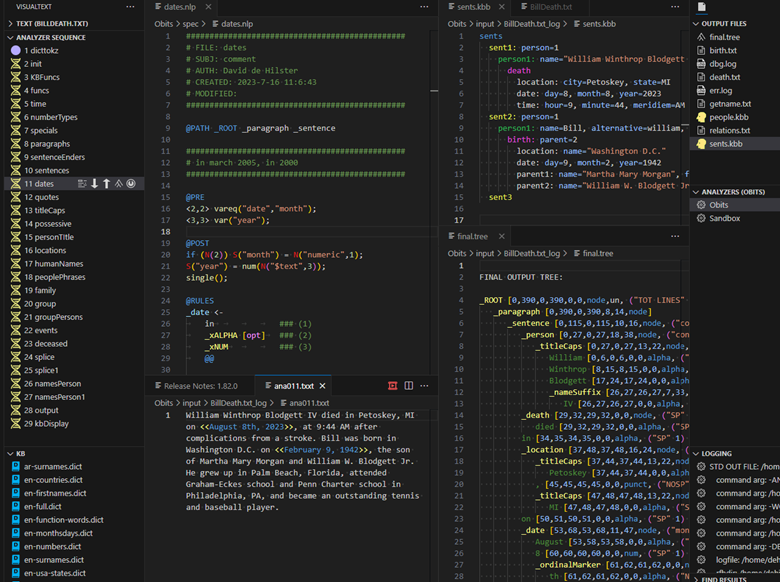
Right Technology at the Right Time
A number of years back, I watched a TED Talk about building successful startups. The number one factor was timing. If a technology is launched at a time when it is greatly needed, it succeeds, no matter what stage the technology is currently at.
For the last two plus decades, NLP++ has remained under the radar. Automatic processes like Machine Learning and Neural Networks were all the rage, and a VP in my last company told a group of university students: there is no longer a need for syntax or semantics in self-learning systems. More recently, large language models like ChatGPT have reinforced the idea that NLP would be solved with self-learning systems.
But ever since ChatGPT has appeared, those closest to NLP and linguistics have pushed back against statistical technologies, saying these systems do not “understand” or “reason”. Noam Chomsky, considered the father of modern linguistics, wrote an op-ed in the New York Times arguing against the idea that AI programs like ChatGPT can truly replicate human thinking and reasoning (read his article for free here).
Anyone using a large language model like ChatGPT soon realizes that these systems are unreliable and “hallucinate”. Human understanding of text relies on knowledge and rules, rather than statistics.
Industry is Looking for a Regex for NLP
A friend in the tech business sent me this tweet:
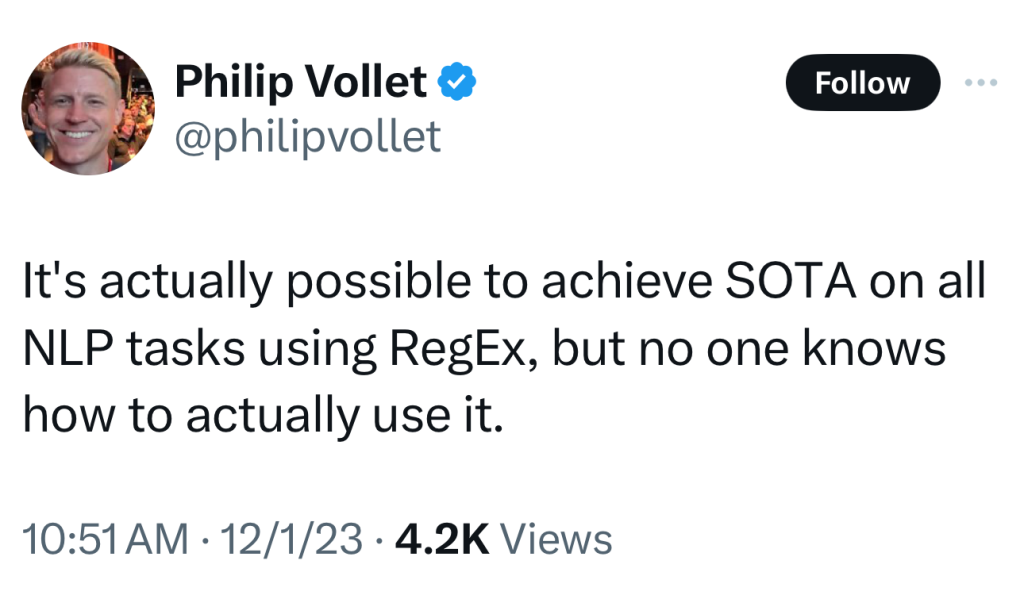
Working with several universities around the world, I have found that there is a strong interest in a rule-based system like NLP++ because it is trustworthy and doesn’t require access to immense amounts of data. One master’s thesis using NLP++ for medical coding is already published, with more student projects to follow. NLP++ will be taught as a university course in India, and other universities are taking notice.
Where are the Other Rule-Based NLP Systems?
Universities were the first to develop pipelined rule-based architectures for NLP. However, each step or silo in the pipeline typically was developed by different students, yielding heterogeneous silos with ad hoc communication between each pair of silos.

These first-generation NLP systems then turned to statistics and, in their haste to fix the insurmountable problems of a siloed system, they traded one problem for another. They turned their siloed rule-based systems into statistical ones and now suffer from the same problems.
NLP++ is, to date, the only “Second Generation” NLP rule-based system that exists in computer science. No other framework is uniform across all parts of the pipeline. NLP++ can mimic what humans do when reading and understanding text. The NLP++ pipeline silos operate synergistically, and problems can be fixed in a logical manner.
Investment is Needed to Become the Regex for NLP
Before NLP++ can be called the “Regex for NLP”, time and effort are needed to create building blocks for programmers to address real-world NLP tasks. This includes building comprehensive dictionaries, knowledge bases, and ready-made parsing blocks that the programming world can use and modify to finally achieve rule-based, trustworthy NLP.
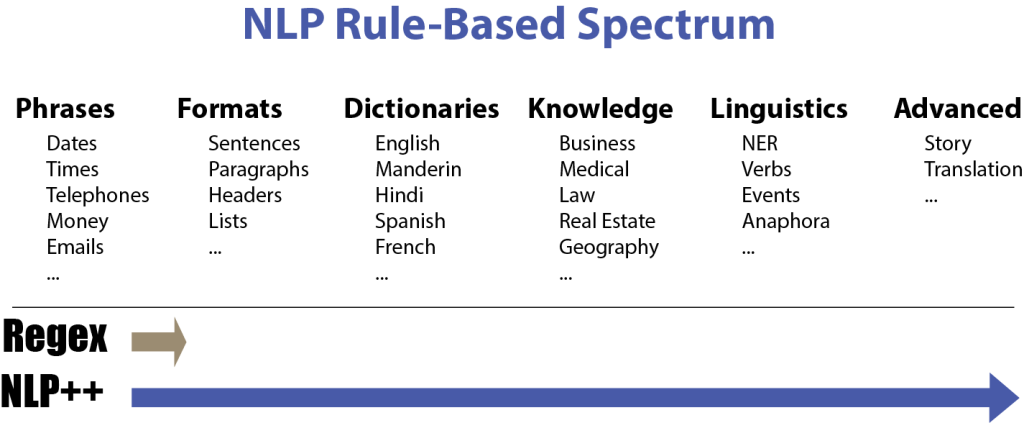
Even without comprehensive knowledge and ready-made NLP++ code, programmers will find NLP++ so much better than Regex, that they will start building more sophisticated text analyzers on their own. I myself use NLP++ at least a dozen times a year to process various types of text files. In fact, NLP++ is a perfect language for parsing a document’s format when the document does not have markup.
Conclusion
With millions of coders around the world using Regex, it is only logical that those same millions will start using NLP++ for their rule-based text processing needs. They will use it because it is immensely more readable and powerful. And once they understand the NLP++ framework, the next natural next step is to apply rule-based parsing without the need for huge resources, training, and data sets. Instead of training with huge banks of computers and expending large amounts of energy, programmers can create NLP analyzers using a small set of data.
NLP++ will democratize NLP and keep the “singularity” in check given that, like Regex, rule-based systems can control exactly how NLP systems learn and interact with humans.

![]()