

This paper compares the Stanford CoreNLP system to the NLP Development Environment that bundles NLP++ and VisualText. I also introduce the terms first- and second-generation NLP Systems.
Introduction
Information extraction from text has been a goal for computational linguists for several decades. In the early 1990s, DARPA sponsored a series of Message Understanding Conferences (MUC) comparing such systems in the domain of terrorism news articles. The task was to extract who did what to whom, when and where. In early MUCs, each team was given 100 articles for development, and all systems were then run on a blind set of 100 articles. The systems were mainly grammar-based, some with a dash of statistical methods.
CoreNLP and NLP++ descend from this bloodline of analyzers. CoreNLP now uses machine learning as an integral part of its processing, while NLP++ does not. CoreNLP is written in Java, and NLP++ is a programming language that compiles to C++. Both support traditional linguistic rule-based methods. NLP++ can be used by novice programmers to create custom analyzers, whereas CoreNLP requires expert computer programmers to properly customize analyzers.
In this paper, I show that CoreNLP is a first-generation NLP parsing system with fundamental flaws and limitations, while NLP++ is a second-generation NLP Development Environment designed for use in real-world systems.
Philosophy of Each
CoreNLP and NLP++ have different philosophies of text extraction. For the sake of this white paper, I define first-generation and second-generation NLP systems below. Numerous first-generation NLP systems exist, while I know of only one second-generation system to date.
| First-Generation NLP System | Rooted in descriptive linguistic grammarOut-of-the-box NLP APIs that annotate textLimited customization by usersThe inventors of the NLP system customize and enhance the systemCommercial licensing is required for proprietary applications |
| Second-Generation NLP System | Rooted in human comprehensionNLP development environment for rapid development of text analyzers100% transparent and customizableNLP programming language that uniformly manages passes, rules, parse trees, knowledge bases, dictionaries, and codeIntegrated end-to-end processingIntegrated visualization tools and interfaces for rapid developmentGrowing open-source libraries of analyzers, dictionaries, knowledge bases, functions, and rule filesMIT license allows free commercial use |
CoreNLP
CoreNLP is a first-generation NLP system rooted in descriptive linguistic grammars having the objective of describing all possible sentences in a language. These grammars were not designed for parsing text introducing intrinsic complications to their parsing algorithms.
First-generation NLP systems have generic architecture built on the premise that parsing and understanding English is already “solved” and ready to use, with minimal or no customization. Users of CoreNLP require turn-key systems that can parse their text, in order to extract their desired information. CoreNLP does allow for limited customization by users. The idea is that users can trust that CoreNLP will correctly parse their text, given that highly skilled computational linguists have developed the technology for decades, so that writing custom NLP systems from scratch is unnecessary and unproductive.
The CoreNLP team works continually to improve the parsing capability, with the hope of achieving human-like accuracy and covering every conceivable text analysis domain and task.
CoreNLP does allow for training neural networks or machine learning frameworks on labeled datasets. It is subject to all the inherent problems with statistical methods, such as lack of available and accurate human-labeled datasets.
CoreNLP currently works out-of-the-box for Arabic, Chinese, English, French, German, Hungarian, Italian, and Spanish, although languages other than English have reduced functionality.
NLP++
NLP++ is a second-generation NLP system rooted in principles of human comprehension. The architects of NLP++ designed constructs that allow for encoding how humans read and comprehend text. Such a system is based on the mechanics of the comprehension of text, not linguistic grammars.
Instead of creating a comprehensive grammar, NLP++ allows for the building of specific contructs for each text analyzer, providing a library of dictionaries, rules, and knowledge bases. The more analyzer that are built, the more code templates can be reused and modified for next text analyzers.
The authors of NLP++ suggest there is a generic framework upon which specific linguistic and world knowledge can be contructed to mimic how humans use read and understand text for specific tasks. The NLP++ architects contend that:
- Humans only use a limited and specific set of linguistic knowledge and processes when performing a specific text analysis task.
- NLP development should only require developing the linguistic and world knowledge needed for a specific reading task, without need for ad hoc extraneous code.
- Users of an NLP development environment should be able to clearly visualize the parsing process end to end, given that text processing can be overwhelming without such visualizations.
- A person need not be a computational linguist to build robust and focused text analyzers.
NLP++ text analyzers focus on restricted domains and tasks, so that only a subset of linguistic and world knowledge is needed when performing data extraction from text – “do what is needed for a task and nothing more”. This approach avoids pitfalls of generic parsers, such as inability to resolve ambiguities. To mitigate the need to write analyzers ”from scratch”, the development framework includes the NLP++ language, tokenizers, reference or starter analyzers, a single parse tree to elaborate, a rule system and functions for tree manipulation, an internal knowledge base, a suite of built-in functions, and ready-to-use dictionaries and knowledge bases. The framework is bundled in the NLP++ language extension for VSCode, making it easy to quickly prototype, develop, and enhance text analyzers. The idea of NLP++ is to allow the user to focus on encoding processes that emulate the way humans do text extraction.
NLP++ progresses by building new libraries of dictionaries, knowledge bases, and NLP++ rule bundles that make the task of developing new analyzers faster and easier. The NLP++ language itself continues to evolve. For example, recent updates cover Unicode, emojis, new dictionaries, and runtimes for Windows, Linux, and Mac.
Processing Flow
Both CoreNLP and NLP++ have a defined flow for executing their analyzers. CoreNLP has a pipeline of annotators, while NLP++ has an analogous analyzer sequence of passes. Each takes in raw text and outputs extracted information.
CoreNLP
The pipeline for CoreNLP is a sequence of “annotators” in the form of java classes that contain functions for doing specific operations, as well as data in the form of java objects. The pipeline flow is specified by a string of annotator names separated by commas. In CoreNLP, pipelines are usually short, ranging from a couple to less than a dozen annotators. Each step of the pipeline produces annotated information inside a CoreDocument – thus the name “annotator” for each step.
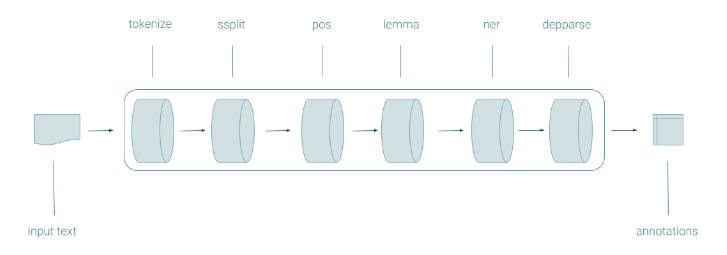
NLP++

NLP++ has an analyzer sequence of passes that hold syntactic rules, function declarations, and code. No data is explicitly exchanged between passes, as done in CoreNLP. Rather, a single parse tree is elaborated by the successive passes, and each pass may “decorate” the parse tree nodes with information. (The root of the parse tree may hold text-wide and analyzer-wide information, for example.) Also, information is posted and accessed dynamically via the analyzer’s knowledge base. A real-world analyzer may include several hundred passes that incrementally develop a “best first” parse and understanding of the input text.
The major difference between the processing flows of CoreNLP and NLP++ is that CoreNLP uses a small number of annotators to do a lot of siloed work, whereas NLP++ typically supports many passes that process the text incrementally and in specific contexts. A single CoreNLP annotator may perform an entire linguistic task such as tagging parts of speech or identifying names, locations, and dates. The passes in NLP++, on the other hand, have no linguistic requirements and extracted information is the result of successively building up an understanding of the text, with the desired extraction being distributed linguistically throughout the process flow.
Data Manipulation
CoreNLP uses java classes for data manipulation and includes objects for tokens, sentences, and documents, to name a few. CoreNLP pipelines produce java CoreDocument objects that contain all the results of the parsing pipeline. Each annotator reads in and updates java objects from the prior annotator. The inventors of CoreNLP offer a set of java classes and objects for tokens and semantic information, but users are free to create their own java classes and objects. Java is not a language specific to NLP.
NLP++ uses an internal tree structure for the processed text, as well as a knowledge base that contains dictionaries and knowledge ingested before parsing, and knowledge constructed and used during parsing. The knowledge base has a hierarchical backbone, and pointers to the knowledge base can be attached to the syntactic tree.
Rule Systems
Both CoreNLP and NLP++ offer syntactic rules.
CoreNLP
CoreNLP uses Stanford framework TokenRegex to define regular expressions over text and tokens, mapping them to semantic objects. It is somewhat based on Java Regex, where rules are written in a json-like language. Regex-style rules are notoriously difficult to read, develop, and maintain. https://nlp.stanford.edu/software/tokensregex.html
([ner: PERSON]+) /was|is/ /an?/ []{0,3} /painter|artist/
The typical TokensRegex sample rule above is arguably difficult to read and understand, suggesting that expert computer programmers are needed for development.
Also, TokensRegex rules are used to build semantic structures, not to modify or build a syntactic tree. When compared to NLP++, this is a limited capability.
Lastly, the TokenRegex annotator appears to lack visualization tools.
NLP++
NLP++ syntactic rules are designed for readability and ease of use. Each pass specifies parse tree contexts within which the rules will execute, elaborating a single “best-first” parse tree. The rules may modify the parse tree and post information to the knowledge base, among other actions.
Both CoreNLP and NLP++ have actions that are triggered when a pattern is matched. CoreNLP’s TokenRegex primarily creates semantic objects, while NLP++ actions can modify the current state of the parse tree, store information in a knowledge base, and perform any desired programmatic task.
Another difference is that CoreNLP requires the program to loop through tokens in order to execute the TokenRegex rules, whereas in NLP++, rules are automatically executed on the current state of the parse tree.
The NLP++ rule system is arguably more readable than TokensRegex, which depends on expert programmers. NLP++ has been successfully learned and used by non-programmers.

Traceability
Traceability is an important part of NLP in real-word systems. NLP++ fully enables traceability, while CoreNLP is limited in this regard.
CoreNLP
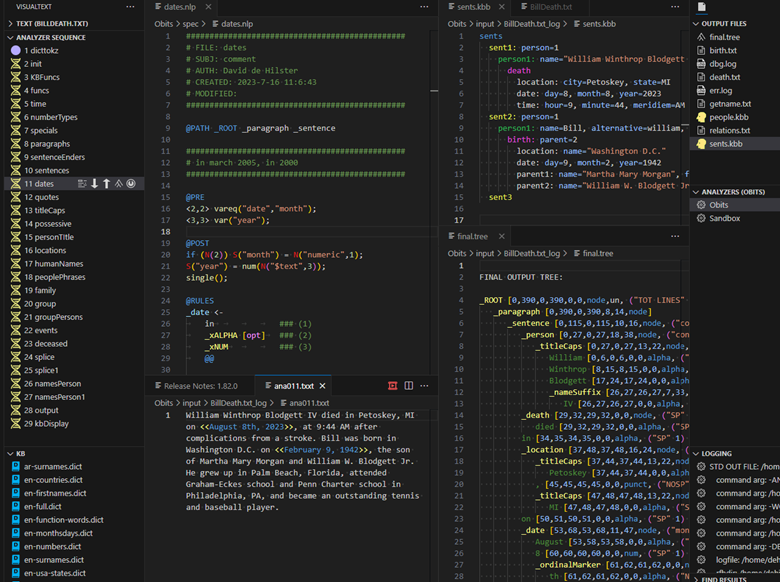
CoreNLP displays the output of each annotator as a tree-like structure, as in the examples below. The CoreNLP documentation states that visualizations are limited.
CoreNLP also relies heavily on machine learning and statistics in the main annotators. The output can be displayed but, since the annotators are “opaque”, there is no explanation for the choices made in building the tree. In many of today’s industries, such as medicine, traceability and explainability are critical.

NLP++
NLP++ analyzers consist of completely transparent computer code, supporting the ability to document, explain, and justify every granular step in the parsing process. The VSCode NLP++ language extension can display both the parse tree and knowledge base at all steps in the process. Logging can readily be implemented to show logical decisions made during the parsing process.
Statistical Methods
CoreNLP makes heavy use of statistical methods in some of its major annotators.
Four of the main annotators in CoreNLP use statistics, machine learning, and/or neural networks. These are: part of speech tagging, named entity recognition (NER), dependency parsing, and coreference resolution.
The disadvantages of statical methods in NLP are detailed in section 16.1 of this white paper.
While NLP++ does not provide statistical and ML methodologies “out of the box”, such capabilities can be implemented as passes within an NLP++ analyzer. For example, a third-party tokenizer has been incorporated in this way. NLP++ can serve as a multi-paradigm development environment.
Customization
Both CoreNLP and NLP++ analyzers can be customized.
CoreNLP
There are several ways to customize CoreNLP.
One is by creating your own sizable annotated text dataset. This can be a daunting task, given that datasets have to be large enough to create an accurate model. This process is long and tedious. Since creating datasets by hand is somewhat impractical, it is suggested that one use the part-of-speech taggers and named-entity recognition to help create the set. Once a training set is prepared and put into the correct format, it is run through the CRFClassifier provided by Stanford.
Another way to customize CoreNLP is to use one of two TokenRegex annotators with your own rules. Users write TokensRegex patterns that map textual expressions into java objects and then use an TokenRegex annotator to process the tokens. One annotator deals with named-entity annotations, while the second is more generic but “more complicated to use” (https://nlp.stanford.edu/software/tokensregex.shtml).
The final way to customize CoreNLP is to write pure java code. The java code takes in java objects from the previous annotator in the pipeline, and continues the processing using library java classes as desired.
In the end, the philosophy of CoreNLP remains the same: to offer a turn-key system with minimal customization. Writing custom annotators that enhance processing for a specific task necessitates considerable development.
In general, customizing CoreNLP is complicated for the average programmer, and readability and maintainability are difficult to achieve.
NLP++
The philosophy underlying NLP++ is to build customized text analyzers that are robust, made for industry, and extensible.
For deep syntactic processing, one may start with the off-the-shelf NLP++ full English parser. The difference between NLP++’s generic parser and that of CoreLogic is that all the NLP++ English parser code is 100% transparent. One can insert custom processing into the generic processor at any level.
But in many instances, it is easier to build an analyzer largely from scratch and borrow capabilities from existing analyzers, given that all analyzers are written in NLP++. Building an analyzer “from scratch” is a misnomer, in that users are starting with the extensive baseline architecture that includes a library of existing dictionaries and knowledge bases, a multi-pass traceable framework, an extensive parse tree framework, and a powerful IDE in the form of an NLP++ language extension for VSCode.
Given the baseline framework, programmers can concentrate on encoding the way humans read a text and extract information for a particular problem.
In order to write an NLP++ text analyzer, the developer should first think about how a human performs that task and make a plan. That plan typically includes dictionaries, knowledge bases, rules, and functions needed for the language, domain, and task at hand. Following that, a typical development strategy is bottom-up and corpus-based. That is, one starts by building a prototype for a single text and expanding that to handle a second text, and so on. By choosing sample texts for variability, one can quickly scale up the capability of the analyzer under construction.
Ease of Use
Ease of use of an NLP system is crucial to its success.
CoreNLP
First-generation analyzers like CoreNLP promise near-perfect output with little or no customization. Users look to them to process their text with simple API calls.
Yet, the output inevitably fails when applied to real-world tasks and texts. The ability to modify and customize an NLP system is a crucial aspect of an NLP text extraction task.
Customizing CoreNLP is difficult, requiring training statistical systems and building rules using TokenRegex. (1) Machine learning has known limitations in NLP, among them the lack of support for explainability. (2) TokenRegex is difficult to read and work with. (3) Computational Linguistic expertise is a prerequisite for meaningful work with CoreNLP.
Because annotators have no real way to peer inside them, traceability is not feasible, so that maintenance and development may be overwhelming for the user. Rather, these fall to the experts who built the original system. The cost and time constraints of relying on the academic CoreNLP team may be problematic.
NLP++
At first glance, the idea that the NLP development environment for NLP++ is easy to use is contradicted by having to write a text analyzer from scratch.
But in real-world use of the NLP++ development environment, both computer programmers and non-computer programmers are capable of quickly building custom analyzers. With VisualText, the NLP++ IDE, users can build analyzers from the ground up and see the results instantly at each step of their analyzer. Given that all humans are experts at some human language, it takes little time for them to think about how they do a specific task when reading text. They can then translate that into actionable language using dictionaries, knowledge, and rules.
As attested by university students from three continents, writing custom text analyzers using VisualText is straightforward and intuitive. Some have declared that this is the only way to encode the desired text analysis.
When asked about using an “off-the-shelf” first-generation NLP system, they noted that such systems were too hard to customize, and that erroneous outputs were difficult to correct.
Non-Linguistic Text Processing
One aspect of NLP deals with text formatting. Resumes are a good example. Before an NLP system can process the text for extracting data, it must know WHERE to look and be able to process formats such as headers, bullets, lists, and tables.
CoreNLP
Except for paragraphs and sentences, CoreNLP requires the programmer to pre-process formatted text. There are no mechanisms for finding sentences within a formatted text. This is left to the user to code by hand using java code, and thus requires a computer programmer versed in CoreNLP.
NLP++
NLP++ on the other hand is a generic framework that treats all text the same. Syntactic rules can be written to parse formatted text into zones, headers, bullets, lists, and prose regions – analogous to the more “linguistic” tasks.
Handling Failure
Handling failure is an important part of natural language processing. Computational linguists posit that parsing natural language will never be perfect, because humans often write text that is unclear or ambiguous. Constraining rich, free-form human language to a restricted format such as a database representation, i.e., “pigeonholing”, often creates inaccuracies, gaps, and disagreements. Human speakers each have their own “idiolect” or unique language model.
Perfect NLP is impossible and will fail at times. NLP systems must be able to handle failure gracefully.
CoreNLP
CoreNLP does not provide specific methods for fixing problems that arise from an erroneous parse. If the annotator uses a statistical model, more examples and training are needed to fix the problem. Negative consequences for such corrective measures include the need for large training sets, built by hand, with no guarantees of a corrected result.
Annotators that use machine learning may fail in illogical or inconsistent ways. In experimenting with CoreNLP’s online demo, a small change to a sentence caused the parse to fail. When examining the two sentences, one cannot necessarily explain the failure.
Below, the two sentences differ only in a comma between the city and state abbreviation, but the system trained for NER does not recognize the location with the comma.
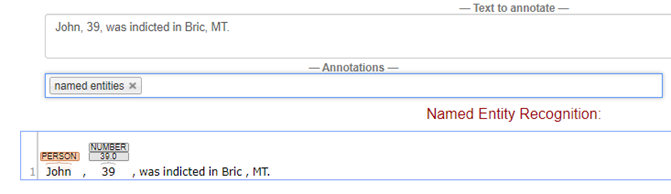
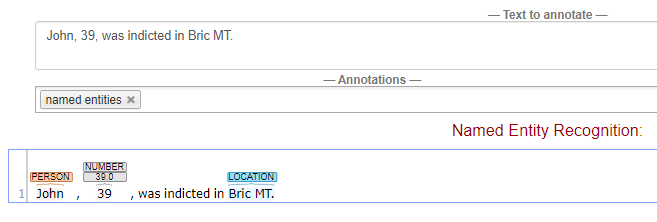
CoreNLP also uses custom annotators to mitigate problems before they arise. Given that CoreNLP requires programming in java, there is no well-defined mechanism or framework for creating these fixes.
CoreNLP expects to correctly annotate text the first time, and users must rely on the expertise of scientists from Stanford to make corrections.
NLP++
NLP++ enables users to pinpoint exactly where a failure has occurred.
One strength of NLP++ is its ability to “fail gracefully”. A real-world case of the NLP++ technology being recognized by industry occurred in the early 2000s, in an evaluation against other NLP technologies. The company doing the testing (Glide Technologies, subsequently acquired by NASDAQ) came across NLP++ after testing almost 100 other technologies. Glide selected VisualText/NLP++ because, among other reasons, they could not “break” it conceptually or algorithmically.
NLP++ analyzers are typically built for restricted text analysis domains and tasks. When the analyzer does not find what it is looking for, it frequently outputs “nothing”, so that spurious outputs are minimized.
When erroneous output is produced by an NLP++ analyzer, full transparency (or “glass box”) enables tracing through the process step-by-step to pinpoint and fix the problem. Additionally, verbose and logging outputs can help isolate when and where a failure or omission has occurred. Visualization and highlighting tools assist here as well. For example, highlighting all nouns in a text view shows which were missed and which were erroneously tagged.
Improving the System
First-generation systems like CoreNLP and second-generation systems like NLP++ differ substantially in their support for developing and improving an NLP system. CoreNLP has a theoretical ceiling whereas NLP++ does not.
CoreNLP
CoreNLP requires its processing systems to be complete and ready-to-use. Pre-built parsers are offered with the promise that the experts building them will eventually solve all problems found.
CoreNLP commits to an architecture comprising a few siloed annotators with a particular linguistic model, which is limiting. To make meaningful improvements, one must write pure java code for NLP development. Improving the general annotators is left to the experts who invented the technology. Most customization by users is done via training with machine learning, which at some point hits an accuracy ceiling.
NLP++
NLP++, on the other hand, is an open framework claiming that a flexible multi-pass sequence, dictionaries, knowledge bases, syntactic trees, pattern matching rules, and unifying programming language are all required to build text analyzers without obstacle.
When a problem is found, it can be identified and corrected in a principled way because the code, knowledge and processing are all transparent (“glass box”). When greater accuracy is needed, an analyzer can be augmented with more precise dictionaries, knowledge bases, and functions. When an obstacle is encountered, new methods, algorithms, and even paradigms can be incorporated as needed to overcome it.
Real Text
Real texts are of many types and involve issues beyond the processing of clean and grammatical text sentences.
Social media (e.g., tweets) are a primary example of texts processed by sentiment analyzers. Such texts may be terse and ungrammatical, and laden with emojis and various types of clutter.
Resumes are a primary example of documents with a limitless variety of formats. Every resume author wants their document to stand out from the crowd.
Real texts may be far from pristine. Some applications rely on “dirty” and “lossy” text converted from images via OCR. An example is real estate and court documents registered at USA county clerk offices.
NLP++ has been successfully applied to all the issues mentioned here. The same cannot be said for CoreNLP.
Commercial Use
CoreNLP claims to have users in industry and government, while NLP++ text analyzers have run in real-world applications in industry (detailed below).
CoreNLP
CoreNLP is used commercially, according to their Github repository ReadMe file:
“Stanford CoreNLP is a set of stable and well-tested natural language processing tools, widely used by various groups in academia, industry, and government.”
We cannot find any public lists of industry or government groups using CoreNLP websites, and have contacted Stanford for an active list. We have also searched for companies using the technology and have found none so far.
Stanford has yet to reply.
NLP++
NLP++ and VisualText were developed originally by Text Analysis International, Inc (1998 through 2018), website at textanalysis.com. Notable customers included NASDAQ for sentiment analysis, IBM Global Services UK for government documents, Michael Page International for resume analysis, Educational Testing Service for natural language generation of test questions, and NewVision Systems for real estate document processing in various USA county clerk offices.
A large number of NLP++ analyzers were developed for these and other customers and projects, spanning fields such as medical, legal, financial, historical documents, and scientific literature.
Comparison
Following is a side-by-side comparison of some of the more notable features in CoreNLP and NLP++.
| Tool | CoreNLP | NLP++ |
| Computer Language | Java | NLP++ (compiles to C++) |
| Processing Flow | Pipeline: list of Annotators | Sequence of NLP++ passes, tokenizer being first |
| Available modules | Built-in Annotators: 24 for English, many using statistical methods | Prebuilt analyzers, passes, KBs, and code libraries: E.g., tokenizers, dictionaries, sentence separation, full English Parser |
| Tokenization | Tokenizer: annotator class, not customizable | Initial black-box tokenizer with customized tokenization in subsequent passes |
| Rule Systems | TokensRegex: write java code to traverse tokens and apply the regex-like rules that then generate java objects | NLP++ Rules and associated code apply in each pass of the analyzer, with visualizations of matched patterns in the text and parse tree. |
| Customization | Custom Annotator: Java class with java code | NLP++ passes holding user-built rules, code, and functions (fully customizable) |
| Dictionaries | Dictionary lookup, pattern matching: custom java code on annotator classes, no built-in rule system | NLP++ dictionaries for English and other languages, names, dates, numbers, function words, and more |
| Parts of Speech | Part of Speech Tagger: trained system, not rule-based (opaque) | Passes from full English Parser, also a full English dictionary with parts of speech (transparent rule and code passes) |
| NER | Named entity recognition: machine learning, trained system (opaque) | E.g., NER within the full English Parser usable in other analyzers (transparent) |
| Output | Output: document class with built-in or custom annotator classes | Output: text, csv, json, xml, html, etc. As always, fully customizable |
| Development Environment | Limited visualization tools, any java programming IDE, if available | VSCode NLP++ language extension using colorized human-readable text files to display rule matches, trees, knowledge bases, dictionaries, and NLP++ code |
| Traceability | Only between annotators | 100% traceable and justifiable at all levels of processing |
| License | Commercial License required | Free software license (MIT) |
Conclusion
CoreNLP and NLP++ have numerous features in common. A processing pipeline, tokenization, parsing, and tree building. However, because CoreNLP is a first-generation NLP system, it has flaws that cannot be easily resolved. NLP++, a second-generation NLP system, features a transparent development environment that shifts the focus from building “the one” analyzer for all text to building focused, robust analyzers that can be steadily improved until they match or in some cases surpass human performance.
CoreNLP has various flaws that cannot be resolved: heavy reliance on statistical methods, philosophy of one-size-fits-all generic analysis, and licensing. NLP++ requires manual development, but this is mitigated with a full development environment, reference analyzers, dictionaries, knowledge bases, and more.
Reliance on Statistical Methods
First-generation NLP systems inherit all the problems associated with statistical methods. CoreNLP relies heavily on statistical methods, while NLP++ does not.
We are reminded daily of the limitations of statical methods when seeing computers and cellphones make grammar and spelling errors.
No Guarantee of Fixing Errors
The only guarantee of fixing problems is to logically show where they exist. Statistical systems make decisions based on training and are not logical, making it impossible to logically isolate a problem. The only way to improve such systems is to train the system on ever larger labeled data sets, with the hope that the problems are corrected. There is no guarantee that training will fix a problem.
Ceiling
Annotators in CoreNLP that use statistical processes will eventually reach a plateau, beyond which it will be difficult to incrementally improve.
NLP++ has no comparable ceiling. NLP++ analyzers can be continuously enhanced over time. As needed, new algorithms, methods, and even paradigms may be added to an analyzer’s mix of tools.
Relying on Human Labeled Sets
All statistical processing in NLP requires an accurate human-labeled training set. Some of the larger human-labeled sets, such as the MIMIC dataset for medical text, are known to have substantial inaccuracies. Training using inaccurate datasets yields correspondingly inaccurate analyzers.
Human labelers are subject to fatigue and their labeling is flawed in many cases.
Finally, one of the biggest problems with ML and NLP is generating enough tagged to produce acceptable results. In ML or NN, the larger the training set, the better the results. It is often deemed impractical for humans to generate the necessary test cases needed to make an accurate ML NLP system and even worse, access to large amounts of text is restricted because of privacy laws.
NLP++ analyzers on the other hand can be developed using a small set of texts relying on the generalization abilities of the human programmer who can create analyzers that will understand unforeseen text.
Traceability
The most important real-world requirements for artificial intelligence and NLP are that systems be transparent and be able to show their decision-making process. This is especially true for mission-critical areas such as healthcare. If any processes use statistical methods, machine learning, or neural networks, it is impossible to show how an extraction or annotation was arrived at. It is unacceptable to allow opaque computer systems to make critical decisions.
Trust is built by being able to explain processing decisions.
NLP++ is 100% transparent, allowing analyzers to explain how a decision was made.
Philosophy of Generic Analysis
CoreNLP, like all first-generation NLP systems, promises a generic parsing system for all text. But testing CoreNLP on unseen texts soon reveals errors and limitations. First generation systems lure programmers with the false belief that a single generic parser written by computational linguists can process their text with little or no customization.
Even human readers must be trained to extract information for a specific task. Likewise, vocabulary, syntactic constructs, and world knowledge may not be covered by generic parsers, leading to erroneous annotations that are difficult to correct. Customization of generic systems is antithetical to the original premise.
NLP++, on the other hand, capitalizes on the fact that humans use subsets of linguistic and world knowledge when extracting information from text in a specific domain.
Licensing
Because it takes so long to build generic parsers, those involved in this effort need to be monetized. Unlike NLP++, CoreNLP offers no computer language (other than java) for analyzer development. Enhancing CoreNLP is difficult, requiring substantial programming and statistical NLP development.
Forty or so years ago, first-generation parsers required many person-years of development. To make a living at this, the business model was to sell this capability as solving a client’s problems out of the box with the decades of linguistic and computational expertise of the creators. Various companies from the DARPA MUC conferences in the 1990s gave way to companies in the 2000s who charged a premium for their expertise.
But as many companies discovered, the generic parsers did not perform adequately for their more specific needs, and customization was extremely expensive. When errors became a liability, companies dropped the first-generation parsers opting for human readers or simply abandoning their efforts.
It is hard to find real companies that claim to be using CoreNLP or Stanford’s parsers. But it is certain that hundreds if not thousands of companies and computer groups have tasked a junior programmer to evaluate CoreNLP, only to abandon it because it could not adapt to their task, was too unwieldy or too expensive.
Academic institutions are, as a rule, less than ideal for commercial product maintenance and timely response to customer needs.
The parser from Stanford requires a license for commercial use. (https://techfinder2.stanford.edu/technology_detail.php?ID=24472). When one obtains the license for the Stanford NLP tools, one is at the mercy of the Stanford team to improve the core processes. And customization for a particular task may be expensive or, in some cases, impossible. From the Stanford page on licensing:
“The inventors continue to modify and extend the parser to handle other languages, to support additional features, and to improve performance and flexibility.”
Because CoreNLP is difficult to customize and relies heavily on statistical methods, its usability and accuracy ceiling appear to be low.
NLP++ on the other hand is 100% free to use and all analyzers, including the full English Parser, are transparent, modifiable, and traceable. People are free to build analyzers, dictionaries, knowledge bases, and rule files that everyone can share.
As yet, it is the only programming language with a generic framework for NLP and, thus, the only second-generation NLP system that corrects the problems of first-generation generic parsers.
Implementation
After looking in depth at CoreNLP, here is my assessment about implementing NLP solutions using CoreNLP and NLP++.
I will assume that machine learning cannot be part of the solution given it cannot justify its output which is a requirement for real-world text analyzers.
CoreNLP
Since the many of the CoreNLP annotators include ML, this would exclude the part-of-speech tagger, the name entiry recognition, and the coreference annotator. That would leave using TokenRegex or something similar like Semgrex and using pure Java classes and objects. Given that TokenRegex is designed to be used in conjunction with the other annotators, its functionality is limited and not suited for using it exclusivel. You are left with writing the entire system in java with some minimal java classes for tokenization.
Most first-generation NLP systems offer complete customization by the inventors which involves a customization fee as well as a license to use it in commercial systems. Since CoreNLP was developed at Stanford, they would be the ones customizing, maintaining, and enhancing the system.
In my opinion, the only true way to leverage CoreNLP is by using its machine learning annotators. And as stated earlier in the conclusion, this is unacceptable in read-world systems and therefore you are left with pure java coding.
NLP++
NLP++ provides an extensive framework for creating text analyzers for specific tasks that are robust and 100% traceable. Its framework allows for creating robust analyzers from a small set of text examples, using the human programmer as a way to generalize the text analyzer. There are dictionaries that can be leveraged as well as numerous open-source analyzers written in NLP++ that can be leveraged. Coupled with its NLP framework, I would classify writing an NLP++ analyzer a well-supported “focused” activity, not one being written from “scratch”.
Although any programmer can use NLP++ without any prior NLP experience, NLP++ is still in the initial phases of development as an open-source architecture and the off-the-shelf modules are still limited. NLP++ analyzers are best architected by those fluent in NLP++ and then handed over to who are using it. VisualText allows the upkeep and enhancements by non-NLP programmers, but those programmers need to become fluent in NLP++.
Final Note
Today, students and programmers find only first-generation NLP systems that give the false impression that NLP is solved. Simply download one of the available NLP packages, give it your text, and it will do all the NLP needed processing. Limited customization is available, but the sales pitch is that NLP is “solved”. They soon find the truth to be very different. Most of the systems that use these first-generation systems are for querying data which are assistants and not data extraction systems.
In industry, human readers are used when data extraction accuracy is critical, even given human shortcomings, such as fatigue.
“True” NLP has all but disappeared from universities and has been replaced by statistical methods. Yet those in machine learning are starting to realize that statistical methods simply don’t work when trying to understand and process text, and that something more is needed. As these universities start to discover NLP++, a second-generation NLP system, they are recognizing that this has the potential to create real data extraction systems from unstructured data.
It is possible that more second-generation systems will evolve in the future but, for now, there is only one. Invented more than 20 years ago and buried under a mountain of promises from statistical methods, NLP++ is now being taken seriously by universities and industry as a viable path to traceable and trusted information extraction from text.
![]()