


Textbook Coming August 2025
Read all about it here:
First NLP++ Textbook on Its Way – Natural Language Understanding Global Initiative
Teaching NLP++
One of the more important projects we are currently working on is the creation of high school and college-level courses on NLP using NLP++. NLP courses at universities almost exclusively concentrate on statistical methods like Machine Learning, Neural Networks, and Large Language Models. NLP courses that do not use statistical methods have all but disappeared from universities and industry. With NLP++, that is going to change.
Our goal with this project is to bring back true non-statistical, rule-based, trustworthy NLP back to computer science departments around the world thus reviving the writing of engineered NL systems and digital human readers.
Using NLP++ as a STEM Course
VisualText is an excellent and fun way to introduce students to one of the STEM topics: computer programming. It uses students’ natural ability to speak a human language and fosters them to be introspective and think about how they read and understand text. This eases them into computer programming by emphasizing “thinking like a human” instead of “thinking like a computer”.
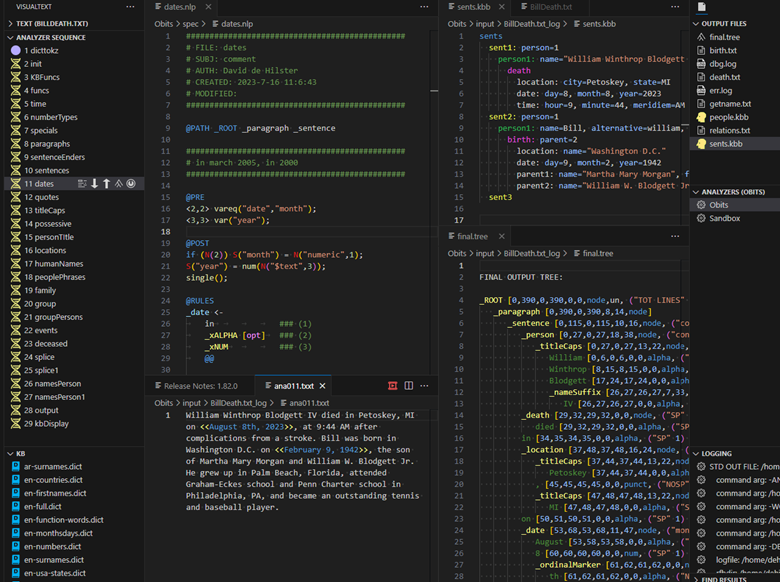
VisualText a programming plugin for the computer code editor VSCode that fosters student’s interest in computer programming by using their natural curiosity about human language. Instead of trying to teach students the intricate complexities of logical computer programming, VisualText allows for students to take a piece of text and to start breaking it down into its components using familiar concepts such as dictionaries and knowledge of patterns such as those found in telephone numbers or dates.
VisualText is a visual editor for the programming language NLP++ that allows students visualize dictionaries, knowledge, and the text itself. All text is automatically broken down into a visual tree structure where students can apply an intuitive rule language to gather words together into patterns. Once target text has been identified and organized, the text and be put into a visual knowledge tree which is easy to build and understand.
Some tasks students enjoy are 1) working on text messages containing abbreviations, emojis and slang, 2) creating chatbots that can understand and store information, 3) creating question-answer programs that can query information in a database. Students will eventually be able to come up with their own projects once they get the hang of “thinking like humans”.

Audience
One of the invaluable components that make NLP++ a success is VisualText. Parse trees, dictionaries, knowledge bases, and NLP rules can be overwhelming to keep track of while building text analyzers. The NLP++ extension for VSCode allows programmers and non-programmers alike to visualize any text analyzer produced using NLP++. Because of this, the audience for NLP++ expands far beyond NLP programmers and computational linguists.
This course can be used for:
- high school to PHD students
- non-programmers who are interested NLP
- computational linguistics
- students interested in trustworthy NLP
- master and doctoral dissertations
- industry wanting to create and use trustworthy digital human readers
Course Objectives
To give students an intellectually stimulating hands-on programming experience to create rule and knowledge base NLP systems from scratch that do not suffer from all the problems associated with statistical methods. NLP++ requires students to analyze how humans read and understand text and translate that into code.
Courses
There are several types of courses that can be taught in NLP and computational linguistics. Here are a couple of suggestions.
NOTE: teachers and professors can use these suggestions as is or they can customize their own courses by mixing and matching any of the topics and exercises found below.
- Course #1: NLP++: Encoding What Humans Think
- Course #2: NLP++ Knowledge Building and LLMs
- Course #3: Ethical and Environmental Implications of NLP++ Versus Statistical Methods
- Course #4: NLP++ for Programmers
Course #1 – NLP++: Encoding What Humans Think
This first course focuses on teaching students to think like humans when reading and understanding text and then translating that into NLP++ dictionaries, knowledge, rules and algorithms.
Course topics
- Thinking like a human: traditional programming requires students to think like a computer whereas programming in NLP++ requires students to think like humans. (see video tutorial)
- Rule based versus statistics: learn the advantages of rule-based systems which do not carry the problems of needing large data sets to train, do not have problems with copyright, and are trustworthy given they are 100% traceable in their decision-making processes. (see article by David de Hilster)
- Bootstrapping and Open Source: discuss with students how NLP++ is open-source and how dictionaries and knowledge can be constructed and shared by all. Talk about what David de Hilster calls the 5th revolution in Linguistics.
- Using VisualText: explain the directories structure for analyzers. Talk about the connectability between trees, text, and rules and discuss the dictionaries and knowledge bases is available in the KB view as well as blocks that are available when creating a new text analyzer.
- Tokenization: NLP++ have various tokenization types available including immediate dictionary lookup to character-based tokenization. Talk about tokenization for emojis and special languages like Tamil and Nepali that have logic in the c++ NLP Engine code for these special cases. Emojis are particularly fun. (see video tutorial)
- Dictionaries: learn about the NLP++ dictionaries files and what is current available with the VSCode NLP++ language extension. Who dictionaries can hold ambiguity information and how students can quickly create dictionaries using NLP++ itself in a bootstrapping method. Instructors and students can take a look at NLP++ co-author David de Hilster’s analyzer repo to see how he used NLP++ to generate many of the dictionaries available today.
- Knowledge base: learn the format of the KBB files and look at the existing KBB files currently available to users. Discuss with students how knowledge can be used to help understand text and even store and use short-term memory while parsing the text.
- Island-Driven, Sequential Processing: learn about how the sequence file works in NLP++ and how that solves many of the combinatoric and ambiguity problems of older traditional rule-based systems. Talk about the different types of nlp files that can be executed and how they work. For example, all functions are parsed from the entire sequence before the analyzer begins. (see video tutorial)
- Trees Versus Knowledge Base: NLP++ has a built-in tree structure and knowledge base. Discuss when one would keep parsed information on a tree and when to include it in a knowledge base. Discuss why being able for tree nodes to be pointing into the knowledge base is crucial for understanding text.
- NLP++ Rules: examine and learn the NLP++ rule system and talk about the power of being able to do a myriad of actions after the matching of rules as well as using preconditions. Discuss the superiority of the NLP++ rules over Regex.
- Anaphora: discuss how NLP++ can solve anaphora in a very human-like way and how it is essential to use the knowledge base for this task. (see video tutorial)
- Ambiguity: teach the built-in mechanisms in NLP++ that help in resolving ambiguity. (see video tutorial)
- Recursion: Learn how to use recursion using NLP++ rules. (see video tutorial)
- Format Parse: discuss how humans parse formatting of a document as much as the content itself. Resumes are excellent examples of this. NLP is not only linguistic in nature, but includes formatting.
Exercises and Tests
- Addresses: This is a great exercise for students to build their first analyzer and learn NLP++’s rule system. It makes them learn how to use existing dictionaries that come with NLP++
- Sentiment analysis: These are very specific and demonstrate to students that sentiment analysis is extremely specific to a subject matter and task and how NLP++ allows students to create analyzers that are finely tuned to that specific task. This can be done by everyone in class given each sentiment analyzer can easily be built from scratch and the variety of these analyzers are limitless (see sentiment by past student interns).
- Resume processing: This is a great exercise for students in that they have to not only deal with text content, but the variation in text format. Processing the formatting of resumes alone is a formidable project in itself and along with processing education, skills, job history etc, this easily can turn into a group project.
- Wiki to Dictionary and KBB Files: Students will deal with using NLP++ to parse the wiki text format to get at content from Wiktionary and Wikipedia pages. (see article and papers)
- Name Entity Recognition: have students tackle this problem as a whole or in parts in a group. This is a harder problem and could be one-project for the entire group.
- Anaphora: write an NLP++ analyzer to resolve anaphora in text. This is a great exercise for students to learn how humans resolve this.
Course #2 – NLP++ Knowledge Building and LLMs
One of the most important aspects of NLP++ is the ability to create trustworthy linguistic and world knowledge including algorithms to use that knowledge in order to read and understand text. NLP++ can take advantage of LLMs by querying them and getting answers back top create new knowledge.
Course Topics
- Knowledge Migration to Computers: discuss what David de Hilster calls the Fifth Linguistic Revolution. Why computers must be “given” certain knowledge and why it can’t learn this simply from statistics and reading text. Discuss how we erroneously assign meaning to statistical relationships and responses from LLMs.
- NLP++ Output to Python: how do you write and NLP++ analyzer to take input from Python and return output. Talk about generating JSON strings and JSON objects using the NLPPlus Python package.
- NLPPlus Python Package: how to use the NLP++ python package. Talk about how the package loads the dictionaries and knowledge bases on initialization and then can call the analyzer multiple times.
- Untrustworthiness of Statistical NLP Methods: talk about statistical methods such ML, NN, and LLMs and how they limit their usefulness in industry. Contrast that to the rule-based system of NLP++.
- NLPPlus Python Package to Create Self-Learning Systems: learn how NLP++ can take untrustworthy data and turn it into trustworthy data that can be used in trustworthy NLP. Discuss why NLP++ cannot fix untrustworthy data that comes out of statistical systems given that statistical errors are not logical. Discuss how using the NLPPlus Python package could be used to create automatic learning systems instead of programmers having to create new dictionary entries or knowledge by hand. (see video tutorial)
- Visual Versus Hidden Problems: discuss how problems in NLP++ are visual and can be easily corrected over statistical methods whose problems are impossible to fix logically. Talk about when NLP++ uses LLMs or a webpage that if the information is incorrect, humans will spot it and correct it – something not possible with statistical methods.
Exercises and Tests
- Building Dictionaries and KBs: have students use NLP++ to build new dictionaries and KB files for NLP++ and the open-source project. Have students look at David de Hilster’s analyzer repo where he stores his NLP++ analyzers that build many of the dictionaries and KBs that are in the NLP++ library.
- Self-Learning Systems with NLP++ and NLPPlus: create an NLP++ analyzer to do a specific task. Identify unknown words or concepts. Use the NLPPlus Python package to call a webpage or LLM find the unknown word or knowledge. Call a second NLP++ analyzer to read the answer and create new dictionary or world knowledge.
Course #3 – Ethical Implications of NLP++ Versus Statistical Methods
With statistical NLP, there are ethical and environmental issues that need to be addressed. This course will introduce students to these topics and how the compare with NLP++.
Course Topics
- Ethical Implications of Statistical NLP Methods: Copyright, access to private data are legal problems that plague statistical methods. The huge costs of large language models make it only accessible to huge tech companies leaving others behind.
- Environmental Implications of Statistical Methods: In order to increase accuracy and coverage, more and more tokens are needed and bigger and bigger systems., The monetary and Enviromental costs are substantial and is it all worth it given statistical models will always be wrong.
- Ethical NLP Development: NLP++ was developed with ethical concerns—such as privacy, bias, and AI ethics—in mind. Its transparent and prescriptive nature leads to responsible and fair NLP applications.
- Practical Applications: NLP++ is not just a research tool; it is a framework built for real-world conditions. It is scalable across various industries, including healthcare, legal, and finance, where accuracy and traceability are paramount.
- Educational Impact: NLP++ serves as an educational tool, helping students and developers understand the intricacies of human language processing. It bridges the gap between theoretical linguistics and practical NLP development, making it an invaluable resource for learning and innovation.
- Singularity: will statistical methods eventually lead to uncontrolled AI and conversely, will NLP++ allow us to avoid the singularity?
Exercises and Tests
- Pick an NLP application and write about the ethical and environmental implications if using statistical methods versus rule and knowledge based.
- Come up with a course for high school students that teaches them the ethics and environmental impacts of statistical NLP methods and include NLP++ as a contrasting technology.
Course #4 – NLP++ for Programmers
NLP++ is a programming language that all programmers should know and learn. All programmers come across files that they need to process that neither Regex nor NLP Toolkits can solve. It could be html files, xml files, or text documents which need to be skimmed to perform a particular task but is way too complex for Regex and which are too specific to use generalized NLP toolkits.
Programmers can use NLP++ to perform tasks on text that before were simply not practical or deemed impossible.
Course Topics
- History of NLP++: talk about the journey of co-authors Amnon Meyers and David de Hilster and how they arrived at the conceptual grammar, NLP++, and VisualText. Talk about how the trees, rules, functions, and knowledge base work together to mimic how humans read and understand text.
- Comparing NLP++ with Regex: discuss readability and the limitations of Regex. Talk about how the tree structure, NLP++ rule system, the conceptual grammar combine to allow for mimicking human beings ability to skim text and perform useful tasks.
- Comparing NLP++ with Traditional NLP Python packages: talk about the problems with generic NLP as well as the inability of traditional packages to be modified.
- NLP++ Language Extension for VSCode: have students download the NLP++ language extension and talk about the Text view, Analyzer view, KB view, and bottom panel Output, Analyzer, Find, and Log views.
- NLPPlus Python Package: discuss the NLP++ Python package and how to use the standard NLP analyzers that come with it. Discuss how to build NLP++ analyzers that return usable data back to Python including the output.json file, and using the JSON functions in KBFuncs.nlp.
Exercises and Tests
- Do not translate tags: have students pick a document that has computer code embedded (perhaps a computer language manual) and build an NLP++ analyzer to add <do_not_translate> tags.
- Database mining: have students find webpages with information that can be put into structure data. Use NLP++ and compare it to using something like the Python package BeautifulSoup. Which one is simpler on which types of webpages? Which one is more readable and more maintainable?
- Contribute to the NLPPlus library analyzers: have students find a specific Python package that parses telephone numbers or other simpler patterns. Recreate that in NLP++ and submit it to github to be included in the NLPPlus library of analyzers that can be used in edited by python programmers.
Contact Us
If this course is interesting to you, please contact us and we will be happy to work with you and your school to implement a course!
![]()